Explain the concept of Retrieval Augmented Generation (RAG) in the context of Generative AI. The slide should focus on how RAG addresses the limitations of Large Language Models (LLMs) by incorporating external knowledge sources. Explain how the RAG loop works, emphasizing the role of the retriever and its connection to indexed knowledge. Highlight the benefits of freshness and grounding that RAG brings. Visually represent the flow of information in a RAG system, including the user, retriever, model, and the final answer.
Start by setting the scene: two dominant generative families — LLMs for text and diffusion for media.
Explain LLMs simply: they predict the next token, which lets them compose, summarize, and plan.
Explain diffusion succinctly: they denoise step by step to create images and audio.
Shift to the right diagram: walk left to right — a user question enters the Retriever first.
Highlight the Retriever as the neon box: it pulls chunks from your Indexed Knowledge, which keeps answers fresh.
Emphasize grounding: retrieved context anchors the model’s generation, reducing hallucinations and enabling citations.
Follow the arrows as they draw: User to Retriever, Retriever to Model, then Model to Answer — that’s the RAG loop.
Close with why this matters: RAG gives you freshness and grounding without retraining the base model.
Behind the Scenes
How AI generated this slide
Conceptualize layout: Divide the slide into two sections - one for textual explanation and the other for a visual representation of the RAG process.
Structure content: Outline key concepts of LLMs, Diffusion models, and the RAG loop, focusing on freshness and grounding.
Visualize RAG flow: Design a diagram with nodes representing User, Retriever, Indexed Knowledge, Model, and Answer, connected by arrows indicating the flow of information.
Implement animations: Add subtle animations to the arrow to highlight the dynamic nature of the RAG process, focusing on the Retriever and its interaction with Indexed Knowledge.
Refine visuals: Choose a clean and modern design with appropriate color palettes, fonts, and visual hierarchy to enhance readability and engagement.
Why this slide works
This slide effectively explains the RAG concept by combining concise textual descriptions with a clear visual representation of the data flow. The animations enhance the visual appeal and draw attention to the key components of the RAG loop. The use of contrasting colors and clear typography improves readability and comprehension. The slide's content is structured logically, starting with an introduction to LLMs and Diffusion models, and then focusing on the RAG process and its benefits, making it easy for the audience to follow along. The slide incorporates relevant SEO keywords like 'Generative AI', 'RAG', 'LLMs', 'Retrieval Augmented Generation', 'Freshness', and 'Grounding' to enhance its discoverability.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is Retrieval Augmented Generation (RAG)?
RAG is a technique used in Generative AI to enhance the capabilities of Large Language Models (LLMs) by allowing them to access and incorporate external knowledge sources. This allows for the generation of more accurate, comprehensive, and up-to-date responses by grounding the LLM's output in reliable information.
How does RAG work?
The RAG process typically involves a 'retriever' component that searches for relevant information within an indexed knowledge base based on a user's query. The retrieved information is then provided as context to the LLM, which uses it to generate a response. This loop ensures that the generated output is grounded in factual information and remains fresh with updates to the knowledge base.
What are the benefits of using RAG?
RAG offers several advantages. It enhances the 'freshness' of the generated content by incorporating the latest information from the knowledge base. It improves 'grounding', meaning the outputs are less likely to be hallucinated and more likely to be factually accurate. It also allows for citing sources, increasing transparency and trust in the generated information.
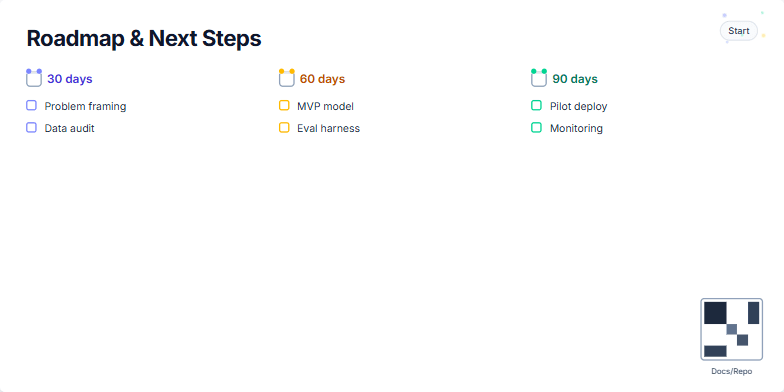
Create a slide visualizing a 30/60/90 day roadmap for a project. The roadmap should include key milestones for each phase, such as problem framing and data audit (30 days), MVP model and evaluation harness (60 days), and pilot deployment and monitoring (90 days). The slide should have a clean and modern design, incorporating a progress indicator or timeline element. Include a 'Start' badge to signify the beginning of the roadmap. The slide should also include a subtle visual element to draw attention to the start of the roadmap. A small, unobtrusive QR code linking to relevant documentation or repository should be placed on the slide. The overall tone should be professional and project-oriented, emphasizing clear goals and progress tracking.
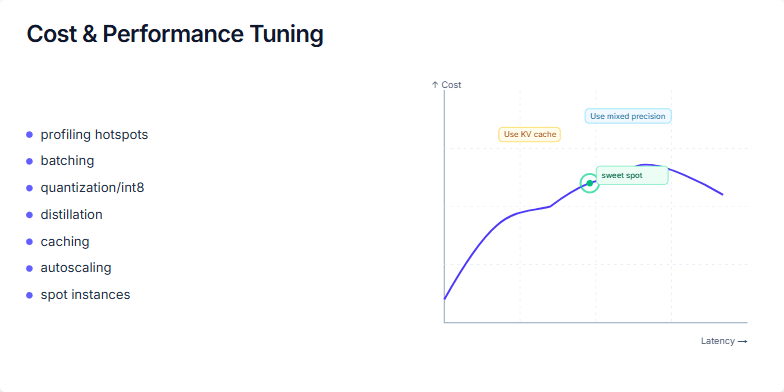
Create a slide about cost and performance tuning, emphasizing the importance of finding a balance between the two for optimal business outcomes, not just raw speed. The content should cover strategies for achieving this balance, including profiling, batching, quantization, distillation, caching, autoscaling, and spot instances. It should also visually represent the relationship between cost and latency, highlighting the 'sweet spot' where optimal balance is achieved. Include specific examples like using KV cache or mixed precision to operate near this sweet spot. Finally, emphasize the iterative nature of this process and the need for continuous monitoring and adjustment.
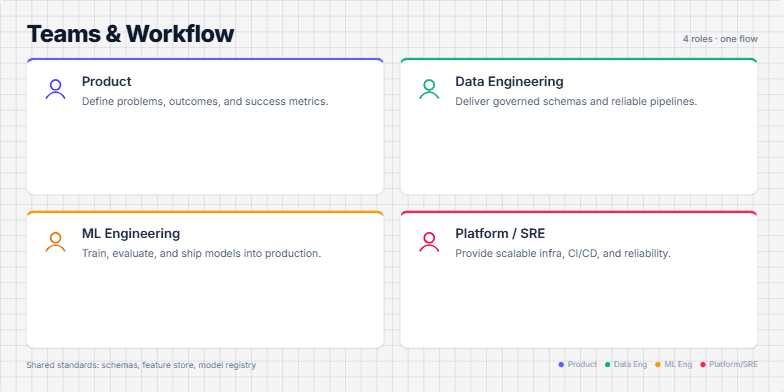
This slide visually represents the workflow and collaboration between different teams (Product, Data Engineering, ML Engineering, and Platform/SRE) involved in a product's lifecycle, from ideation to production. It emphasizes the roles and responsibilities of each team and highlights the importance of shared standards (schemas, feature store, model registry) for a streamlined and efficient process. The slide uses distinct colors and icons for each team, facilitating quick comprehension of their respective contributions. The animation further enhances engagement by sequentially introducing each team's role.
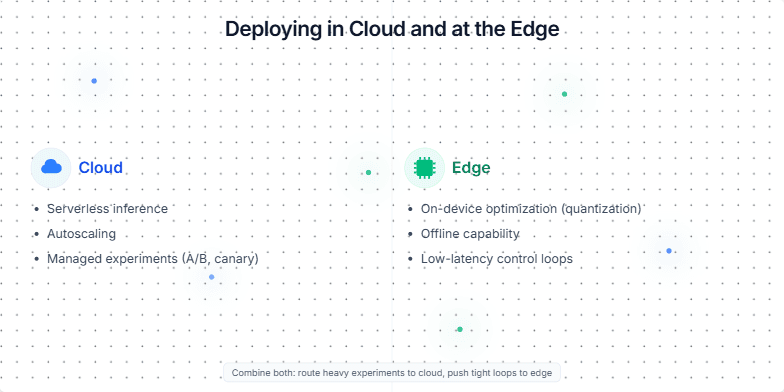
Create a slide that compares and contrasts deploying machine learning models in the cloud versus at the edge. Highlight the advantages and disadvantages of each approach, and suggest scenarios where one might be preferred over the other. The slide should be visually appealing and easy to understand, using clear language and concise bullet points. Consider using icons or visuals to represent cloud and edge deployments. The target audience is technical professionals and business stakeholders who are involved in making decisions about ML model deployment.
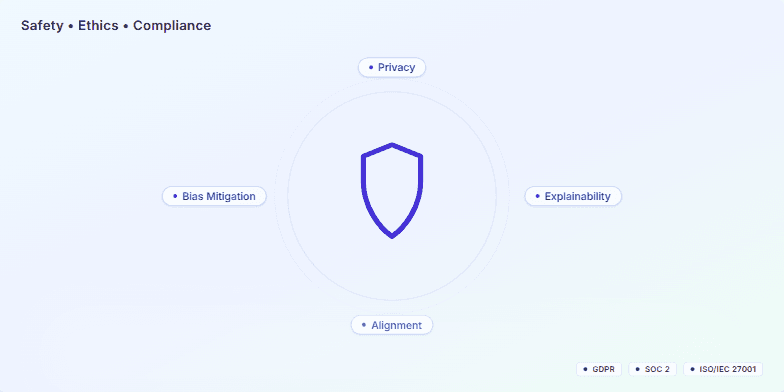
This slide is for a presentation about our commitment to safety, ethics, and compliance in developing and deploying AI-enabled systems. It visually represents our core principles: Privacy, Bias Mitigation, Explainability, and Alignment. The presentation emphasizes these are not mere add-ons but fundamental to our product development process. It also highlights our adherence to industry standards and regulations like GDPR, SOC 2, and ISO/IEC 27001, showcasing our dedication to responsible AI practices. The target audience includes potential clients, partners, and internal stakeholders interested in understanding our approach to AI governance and ethical considerations.
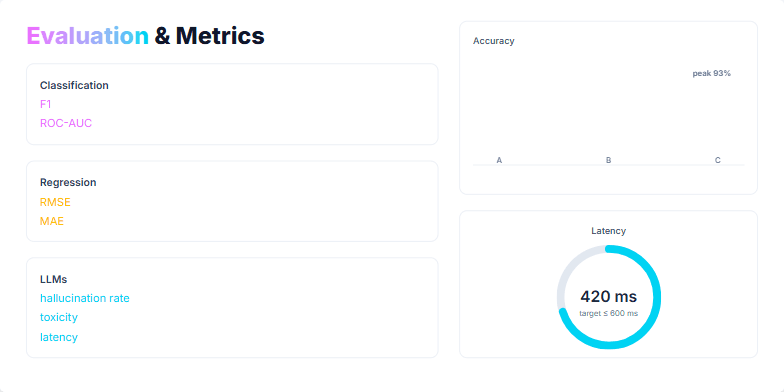
This slide visually represents the evaluation metrics used for different machine learning tasks, including classification, regression, and LLMs. It showcases how to visualize progress and performance using metrics like F1, ROC-AUC, RMSE, MAE, hallucination rate, toxicity, and latency. The slide includes a bar chart comparing accuracy across different models and a gauge visualizing latency against a target. The purpose is to emphasize the importance of selecting appropriate metrics for each task, visualizing them effectively, and focusing on metrics that directly impact user outcomes.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.