An Overview of Multimodal AI Architectures for Vision, Audio, and Video Processing and Their Applications
Description provided by the user:
The user requested a technical presentation slide that clearly compares and contrasts the architectures of multimodal AI systems across three key domains: vision, audio, and video. The slide needed to visually break down the typical processing pipeline for each modality, from initial encoding to final reasoning with a Large Language Model (LLM). It was also important to showcase practical applications or tasks associated with each type of model, such as OCR for vision, ASR for audio, and step extraction for video. The design should be clean, organized, and easy to follow for an audience with some technical background in AI.
Open by framing the slide: three parallel pipelines for vision, audio, and video. We’ll reveal them left-to-right and briefly connect model blocks to real tasks.
First, Vision (VLM). Explain the diagram: a vision encoder like ViT or CLIP turns pixels into embeddings. A projector aligns these with the LLM’s token space. The LLM handles reasoning and generation. Point to tasks: OCR, chart question answering, and general VQA. Call out the example thumbnail with bars and detection boxes to hint at OCR and chart parsing.
Second, Audio. Describe the front end: waveform to mel spectrogram. An audio encoder produces representations that feed a text decoder or LLM. Emphasize the bi-directional nature: ASR and TTS, plus audio captioning.
Third, Video. Note the temporal dimension: either sample frames or build spatiotemporal tokens. A projector adapts these to the LLM. Tasks include step extraction from instructional videos and grounding actions in time.
Close by connecting the patterns: modality-specific encoders produce aligned tokens, a small projector bridges to a general LLM, and the LLM performs reasoning. Encourage questions on choices like frame rate, spectrogram parameters, and projector design.
Behind the Scenes
How AI generated this slide
Deconstruct the request into three parallel tracks for Vision, Audio, and Video, establishing a three-column grid layout as the core structure.
For each modality, define the standard architectural pipeline: a specialized encoder (ViT, Audio Encoder), a projector for modality alignment, and a large language model (LLM) for reasoning. This forms the 'Flow' component.
Identify and list key tasks for each domain to demonstrate practical applications. These are rendered as 'chips' for easy readability, covering concepts like VQA, ASR, TTS, and video grounding.
Create abstract, minimalist thumbnail graphics for each modality (a bar chart for vision, a sound wave for audio, and filmstrips for video) to provide quick visual context without complex imagery.
Develop a reusable 'Panel' React component to ensure consistency across the three columns, using props for color, title, flow, and tasks. Color-coding (indigo, teal, amber) is used to visually differentiate the modalities.
Implement subtle entry animations using Framer Motion for each panel to guide the viewer's focus sequentially, enhancing the presentation's narrative flow.
Compose speaker notes that walk through each panel, explaining the technical components and connecting them to real-world tasks, preparing the user for a comprehensive presentation.
Why this slide works
This slide excels because it effectively translates complex multimodal AI architectures into a clear, comparative, and digestible format. The parallel three-column structure makes it easy for the audience to compare the pipelines for Vision Language Models (VLMs), Audio, and Video models side-by-side. Key concepts like 'Encoder,' 'Projector,' and 'LLM' are visually represented as a simple flow, demystifying the process. Using distinct color palettes and abstract thumbnails for each modality enhances visual separation and recall. The inclusion of task-specific 'chips' (e.g., 'OCR', 'ASR') grounds the abstract architectures in concrete applications. This design is highly effective for educational content, technical deep-dives, and strategy presentations on AI, making it highly discoverable for keywords like 'multimodal AI pipeline,' 'vision language model architecture,' 'audio processing with LLMs,' and 'spatiotemporal data analysis.'
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the role of the 'Projector' in these multimodal architectures?
The 'Projector' is a crucial but relatively small neural network component that acts as a bridge between the modality-specific encoder and the Large Language Model (LLM). The vision or audio encoder outputs embeddings in a high-dimensional space unique to its modality. The LLM, however, operates in a different embedding space designed for text tokens. The Projector's job is to translate or 'project' the embeddings from the encoder's space into the LLM's space, so the LLM can understand and reason about the visual or audio information as if it were text.
How do these models handle the temporal dimension in audio and video?
Audio and video models inherently deal with data that unfolds over time. For audio, the input waveform is converted into a Mel Spectrogram, which is a 2D representation of frequency over time. The audio encoder then processes this sequence to capture temporal patterns. For video, models typically either sample individual frames and process them as a sequence of images or use more complex methods to create 'spatiotemporal tokens' that capture both spatial information within a frame and motion across frames. This temporal understanding is critical for tasks like speech recognition (ASR) or action recognition in videos.
Why are different encoders used for different modalities?
Different data modalities have fundamentally different structures. Vision encoders like ViT (Vision Transformer) are designed to process pixel grids and identify spatial features and objects. Audio encoders are built to analyze frequency and time information from spectrograms to understand sounds, speech, and music. Video encoders must handle sequences of frames to capture motion and temporal changes. Using a specialized encoder for each modality is essential for efficiently and effectively extracting meaningful features before they are passed to the LLM for higher-level reasoning.
Create a presentation slide that outlines a technology or product roadmap. The slide should be titled 'Roadmap and Q&A'. It needs to be split into three sections: 'Near-term', 'Mid-term', and 'Long-term', each with a few key bullet points. For the near-term, include tool-use reliability, better evals, and small specialized models. For the mid-term, add on-device/federated learning and energy efficiency. For the long-term, list reasoning, memory, and lifelong learning. The slide should also feature a prominent QR code for attendees to scan for slides and resources, along with a concluding message to open the floor for questions.
The user requested a slide for a business presentation aimed at stakeholders concerned with AI adoption. The goal was to demonstrate a robust and structured approach to managing the inherent risks of implementing large language models (LLMs) and other AI systems. The slide needed to be clear, professional, and reassuring. It should map specific, well-known AI risks (like hallucination and data leakage) to tangible technical solutions and controls, while also linking these efforts to established compliance frameworks like SOC 2 and GDPR to build trust with a corporate audience.
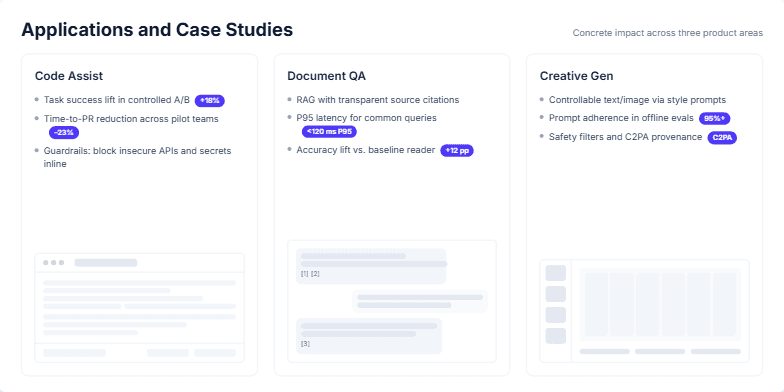
Create a business presentation slide titled 'Applications and Case Studies' that highlights the concrete impact of our AI initiatives across three key product areas. Use a three-column layout for 'Code Assist', 'Document QA', and 'Creative Gen'. For each column, include 3-4 bullet points with specific, quantifiable metrics and key features. For example, show percentage lifts, latency improvements, or accuracy gains. Also, include a simple, abstract visual mock-up for each application to provide context without being too detailed. The overall design should be clean, professional, and data-driven.
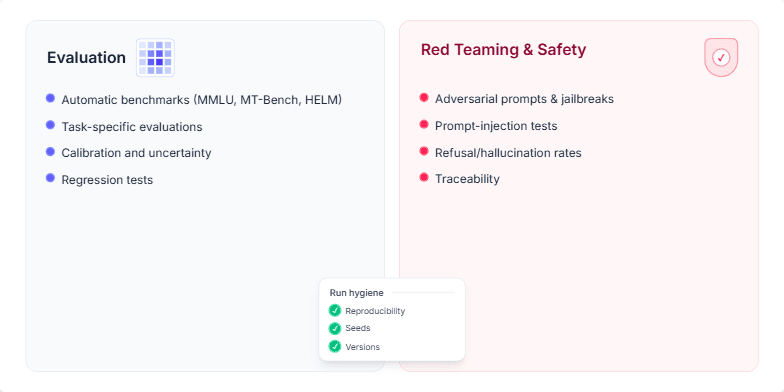
The user requested a slide detailing a company's comprehensive AI model validation process. The slide needed to be split into two main sections: performance evaluation and safety/red teaming. The evaluation part was to include standard benchmarks like MMLU and MT-Bench, task-specific tests, calibration, and regression testing. The safety section required coverage of adversarial prompts, jailbreaks, prompt injection, and metrics like refusal/hallucination rates. A key requirement was to also include a smaller element on 'run hygiene' to emphasize reproducibility, using seeds, and versioning, visually communicating a robust and trustworthy process.
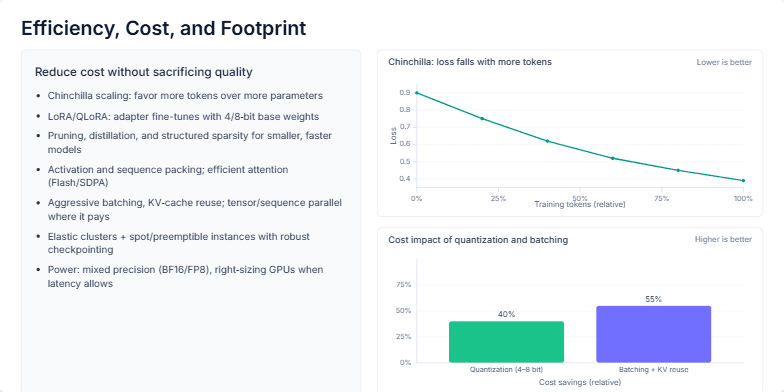
Create a slide for a technical audience about optimizing large AI models. The slide should cover key strategies for reducing cost and computational footprint without sacrificing quality. I want to see a list of techniques, including Chinchilla scaling, LoRA/QLoRA, pruning, and infrastructure tactics like using spot instances. Please include two charts to visualize the impact: a line chart showing how training loss decreases with more tokens (like in the Chinchilla paper) and a bar chart quantifying the cost savings from common inference optimizations like quantization and batching.
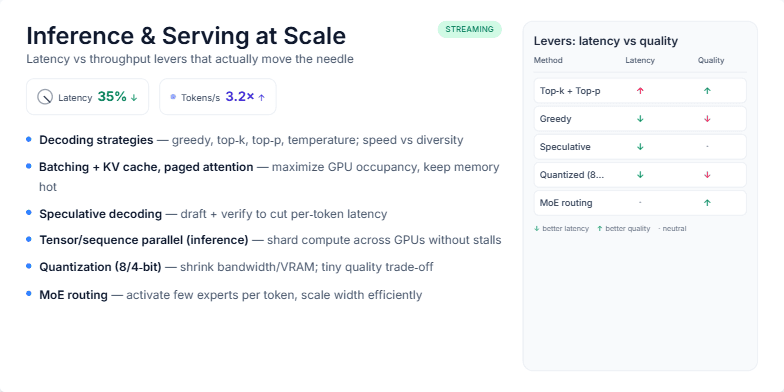
The user requested a technical presentation slide aimed at engineers and data scientists. The slide needs to cover the most effective techniques for optimizing Large Language Model (LLM) inference and serving at scale. It should explain key methods like decoding strategies, KV caching, speculative decoding, and quantization. A key requirement is to visually represent the trade-offs, specifically how each technique impacts latency versus model output quality. The slide should also include key performance indicators, like percentage reduction in latency and increase in tokens per second, to quantify the benefits of these optimizations.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.