Strategies for Scaling Large Language Model Inference: Balancing Latency, Throughput, and Quality
Description provided by the user:
The user requested a technical presentation slide aimed at engineers and data scientists. The slide needs to cover the most effective techniques for optimizing Large Language Model (LLM) inference and serving at scale. It should explain key methods like decoding strategies, KV caching, speculative decoding, and quantization. A key requirement is to visually represent the trade-offs, specifically how each technique impacts latency versus model output quality. The slide should also include key performance indicators, like percentage reduction in latency and increase in tokens per second, to quantify the benefits of these optimizations.
Open by framing the slide: we are optimizing both latency and throughput; the badges show we care about streaming experiences.
Call out the count-up metrics: we often aim for around 35% latency reduction and a 3.2× tokens-per-second gain by combining techniques, not a single silver bullet.
Walk the bullets top to bottom:
First, decoding strategies: greedy, top-k, top-p, temperature. Emphasize the speed–diversity trade-off; greedy is fastest but can reduce quality.
Second, batching with KV cache and paged attention to keep memory hot and ensure high GPU occupancy. This is the biggest lever for serving fleets.
Third, speculative decoding: draft-and-verify reduces per-token latency without significantly hurting quality.
Fourth, tensor or sequence parallelism at inference time: shard computations across GPUs while minimizing synchronization stalls.
Fifth, quantization to 8/4-bit: reduces bandwidth and VRAM, often with minor quality loss; pair with calibration for safety-critical domains.
Sixth, MoE routing: activate only a few experts per token to scale width cost-effectively; be mindful of routing overhead and load balance.
Shift attention to the right panel. Explain the tiny table: arrows indicate how each lever typically affects latency and quality. Green is good relative movement; red is the cost. Neutral dots mean impact is usually minimal.
Close by reinforcing: combine batching, cache-aware attention, quantization, and speculative decoding for the best latency; tune decoding and MoE routing to preserve quality.
Behind the Scenes
How AI generated this slide
First, establish a two-column layout to separate detailed explanations from a high-level summary, enhancing information hierarchy and readability.
In the main (left) column, list the core LLM inference optimization techniques. Group them logically and use `Fragment` components to reveal them sequentially, guiding the audience through concepts like decoding strategies, batching with KV cache, speculative decoding, quantization, and MoE routing.
Develop a summary panel for the right column. This involves creating a concise table that maps each technique to its typical impact on latency and quality, using intuitive visual cues like color-coded arrows (green for improvement, red for degradation) for quick comprehension.
Incorporate dynamic elements to increase engagement. Implement a `CountUp` component to animate key metrics like latency reduction and throughput gain, and use `framer-motion` to animate the appearance of table rows, making the presentation more visually appealing.
Finally, write comprehensive speaker notes (`export const Notes`) to provide a detailed script. This script should guide the presenter in explaining each bullet point, connecting the technical details to the summary table, and reinforcing the key takeaways for the audience.
Why this slide works
This slide is highly effective because it distills complex engineering concepts into a digestible format. The two-column layout expertly separates deep-dive information from a quick-reference summary, catering to different levels of audience engagement. The use of visual aids, such as color-coded trend indicators (↑, ↓, ·) and animated metrics, makes abstract trade-offs between latency and quality tangible and easy to understand. Staggered animations using `Fragment` and `framer-motion` guide the viewer's focus sequentially through the content, preventing information overload. The inclusion of detailed speaker notes ensures that a presenter can deliver a clear, coherent, and impactful explanation, making it a comprehensive tool for technical communication.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the primary trade-off discussed in LLM inference optimization?
The primary trade-off is between performance (latency and throughput) and the quality or diversity of the model's output. For example, 'greedy' decoding is the fastest method but may produce repetitive or less creative text. Conversely, techniques that enhance diversity, like adjusting temperature or using top-p sampling, require more computation. Similarly, quantization can significantly speed up inference and reduce memory usage, but it may come with a minor degradation in model quality.
How does 'Speculative Decoding' reduce latency?
Speculative decoding reduces per-token latency by using a small, fast 'draft' model to predict a sequence of several future tokens at once. This draft is then checked and verified in a single pass by the larger, more powerful main model. Since the large model only needs to run once to approve multiple tokens, instead of once for each token, the overall time to generate a sequence is significantly reduced, effectively cutting down the latency without a substantial loss in quality.
Why are 'Batching + KV cache' considered a major lever for LLM serving?
Batching and the KV cache are crucial for maximizing GPU efficiency in a serving environment. Batching combines multiple user requests to be processed simultaneously, ensuring the GPU's parallel processing capabilities are fully utilized. The KV (Key-Value) cache complements this by storing the intermediate attention calculations for tokens that have already been processed. When generating the next token, the model can reuse these cached values instead of re-computing them, dramatically reducing redundant calculations and boosting overall throughput for the entire serving system.
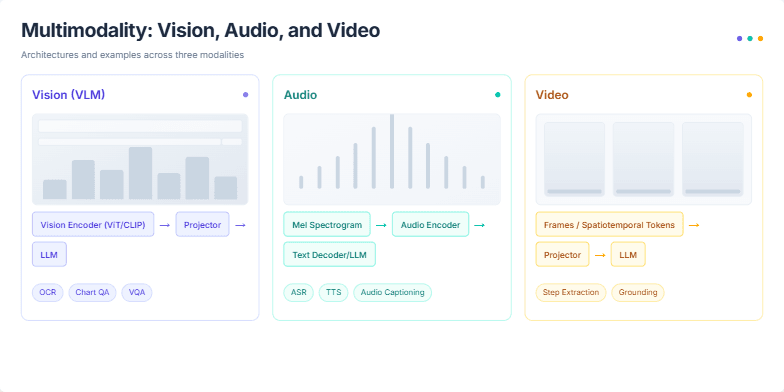
The user requested a technical presentation slide that clearly compares and contrasts the architectures of multimodal AI systems across three key domains: vision, audio, and video. The slide needed to visually break down the typical processing pipeline for each modality, from initial encoding to final reasoning with a Large Language Model (LLM). It was also important to showcase practical applications or tasks associated with each type of model, such as OCR for vision, ASR for audio, and step extraction for video. The design should be clean, organized, and easy to follow for an audience with some technical background in AI.
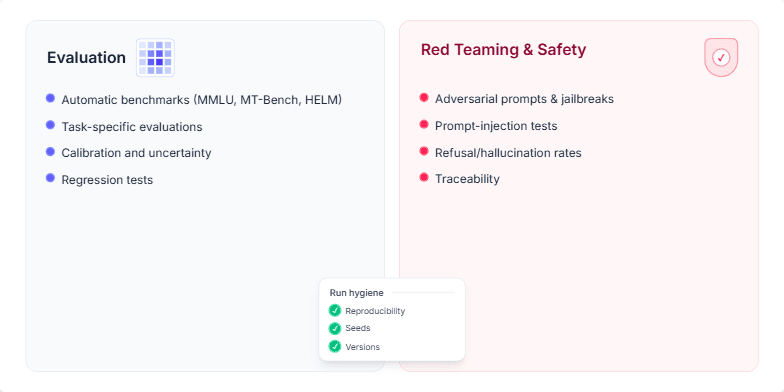
The user requested a slide detailing a company's comprehensive AI model validation process. The slide needed to be split into two main sections: performance evaluation and safety/red teaming. The evaluation part was to include standard benchmarks like MMLU and MT-Bench, task-specific tests, calibration, and regression testing. The safety section required coverage of adversarial prompts, jailbreaks, prompt injection, and metrics like refusal/hallucination rates. A key requirement was to also include a smaller element on 'run hygiene' to emphasize reproducibility, using seeds, and versioning, visually communicating a robust and trustworthy process.
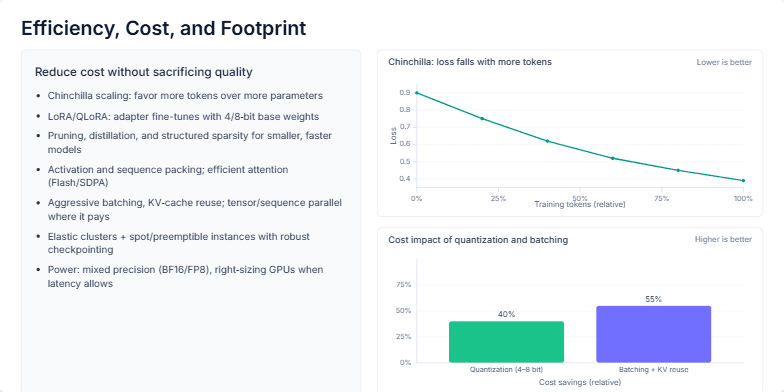
Create a slide for a technical audience about optimizing large AI models. The slide should cover key strategies for reducing cost and computational footprint without sacrificing quality. I want to see a list of techniques, including Chinchilla scaling, LoRA/QLoRA, pruning, and infrastructure tactics like using spot instances. Please include two charts to visualize the impact: a line chart showing how training loss decreases with more tokens (like in the Chinchilla paper) and a bar chart quantifying the cost savings from common inference optimizations like quantization and batching.
A user requested a presentation slide that visually compares three fundamental patterns for building advanced Large Language Model (LLM) applications: Retrieval-Augmented Generation (RAG), Function Calling, and Agentic Loops. The goal is to explain how these techniques contribute to creating AI systems that are both 'grounded' in facts and 'capable' of performing actions. The user asked for a clean, three-column layout, with each pattern having its own distinct color scheme, a simple diagram, and a list of practical development tips for implementation.
The user requested a presentation slide that explains and compares three key techniques for aligning large language models with human preferences: Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO). The goal is to visually break down the process of each method, provide a clear side-by-side comparison of their characteristics like data intensity, stability, and compute requirements, and conclude with the overarching importance of safety layers that are applied regardless of the chosen training method.
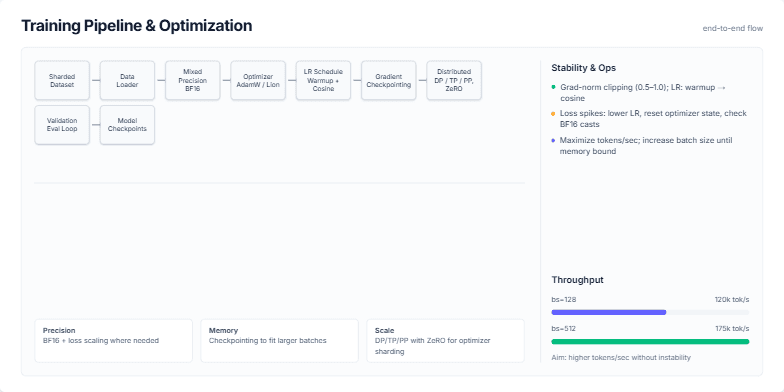
Create a slide that visually breaks down a standard end-to-end training pipeline for a large language model (LLM). It should start from the dataset and go all the way to model checkpoints. For each stage, like data loading, mixed precision, and distributed training, show the key technologies or concepts (e.g., BF16, AdamW, ZeRO). The slide should also include a sidebar with practical tips on ensuring training stability (like handling loss spikes) and a section on optimizing for throughput, showing how batch size affects tokens/second. The overall aesthetic should be clean, technical, and professional.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.