Visualizing a Modern Deep Learning Training Pipeline and Key Optimization Strategies for Stability and Throughput.
Description provided by the user:
Create a slide that visually breaks down a standard end-to-end training pipeline for a large language model (LLM). It should start from the dataset and go all the way to model checkpoints. For each stage, like data loading, mixed precision, and distributed training, show the key technologies or concepts (e.g., BF16, AdamW, ZeRO). The slide should also include a sidebar with practical tips on ensuring training stability (like handling loss spikes) and a section on optimizing for throughput, showing how batch size affects tokens/second. The overall aesthetic should be clean, technical, and professional.
First, set the stage: we’ll walk left-to-right through a practical training pipeline and where we optimize it.
Start with the sharded dataset and the dataloader — emphasize balanced shards and prefetching to keep GPUs fed.
Introduce mixed precision with BF16. Call out that it delivers speed and memory savings while maintaining stability; use loss scaling only if needed.
Move to the optimizer: AdamW is the baseline; Lion can be a drop-in when you want sharper convergence on some workloads.
Explain the learning-rate schedule: warmup to reach a stable plateau, then cosine decay to land smoothly.
Cover gradient checkpointing: trade compute for memory so you can increase global batch size.
At scale, discuss distributed strategies: data parallel, tensor parallel, pipeline parallel; combine with ZeRO to shard optimizer states.
Mention validation as a separate loop and frequent checkpoints for safety and resumability.
On the right, highlight stability tips: grad-norm clipping around 0.5–1.0, and using warmup then cosine decay. For loss spikes, try lowering LR, resetting optimizer state, and reviewing precision casts.
Close with throughput: show that tokens per second grows with batch size, but stop when you hit memory or instability limits. The goal is to maximize tokens/sec while keeping the loss smooth.
Behind the Scenes
How AI generated this slide
First, I'll parse the request for a slide on a machine learning training pipeline. I'll identify the key components: the linear flow (dataset, dataloader, optimizer, etc.), specific technologies (BF16, ZeRO, AdamW), and supplementary sections (stability tips, throughput metrics). This sets the information architecture for the slide.
Next, I'll design a two-column layout. The main, wider column will feature the training pipeline as a central flowchart, making the process flow intuitive. I'll use a sequence of boxes and arrows for clarity. The narrower sidebar will be dedicated to operational advice and performance metrics, providing context without cluttering the main diagram.
I will then implement this layout using React components. I'll create a `StageBox` for each step, an `Arrow` for connectors, and dedicated components like `SidebarBullets` and `ThroughputBars`. This modular approach keeps the code clean. I'll use `framer-motion` to add sequential animations to guide the viewer's eye through the pipeline, enhancing the storytelling.
Finally, I'll populate the components with the specified technical details from the `stages` array and the text for the sidebar. I'll also generate comprehensive speaker notes that mirror the slide's flow, providing a detailed script for the presenter to explain each concept, from sharded datasets to distributed training strategies and maximizing tokens/sec.
Why this slide works
This slide is highly effective because it distills a complex deep learning training process into a clear, digestible visual flowchart. By using a sequential, animated flow, it guides the audience through each critical stage, from data preparation with sharded datasets to advanced distributed training techniques like Data Parallelism (DP), Tensor Parallelism (TP), and ZeRO sharding. The inclusion of a dedicated sidebar for practical 'Stability & Ops' and 'Throughput' metrics provides actionable insights, a key element for technical presentations. The clean design, use of whitespace, and subtle animations from Framer Motion create a professional and engaging user experience. The code is well-structured with reusable React components, making it maintainable and a great example of modern web development practices for data visualization. It effectively communicates advanced concepts like BF16 mixed precision, gradient checkpointing, and LR schedules, making it a valuable resource for ML engineers and data scientists.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the purpose of BF16 Mixed Precision in a training pipeline?
BF16 (BFloat16) mixed precision is a critical optimization technique used in modern deep learning training to improve performance and reduce memory consumption. It involves performing most computations and storing weights and activations in the lower-precision 16-bit BF16 format, while keeping certain critical parts, like the master weights in the optimizer, in 32-bit floating-point (FP32) for stability. This approach significantly speeds up matrix multiplication on compatible hardware like modern GPUs and TPUs and roughly halves the memory footprint, allowing for larger models or bigger batch sizes. The slide highlights this as a key stage for balancing speed, memory, and numerical stability.
How does Gradient Checkpointing help with memory issues?
Gradient checkpointing, as mentioned in the pipeline, is a memory-saving technique that trades compute for memory. During the forward pass of training, instead of storing all the intermediate activations needed for backpropagation, it only saves a small subset (the 'checkpoints'). During the backward pass, it recomputes the discarded activations on-the-fly between these checkpoints. This drastically reduces the memory required to store activations, which is often a bottleneck. This allows engineers to train much larger models or use larger batch sizes than would otherwise fit in GPU memory, at the cost of a modest increase in computation time (typically ~20-30%).
What are DP, TP, PP, and ZeRO in the context of distributed training?
DP, TP, PP, and ZeRO are different strategies for distributed training, which is essential for training massive models across multiple GPUs or machines. DP (Data Parallelism) replicates the model on each GPU, but feeds each one a different slice of the data batch. TP (Tensor Parallelism) splits individual layers or tensors of the model across GPUs, so that different GPUs work on different parts of a single large matrix multiplication. PP (Pipeline Parallelism) splits the model's layers sequentially across GPUs, forming a pipeline where one GPU's output is the next one's input. ZeRO (Zero Redundancy Optimizer) is an optimization that works alongside these strategies; it shards the optimizer states, gradients, and model parameters across the GPUs, significantly reducing the memory footprint on each individual device and enabling the training of colossal models.
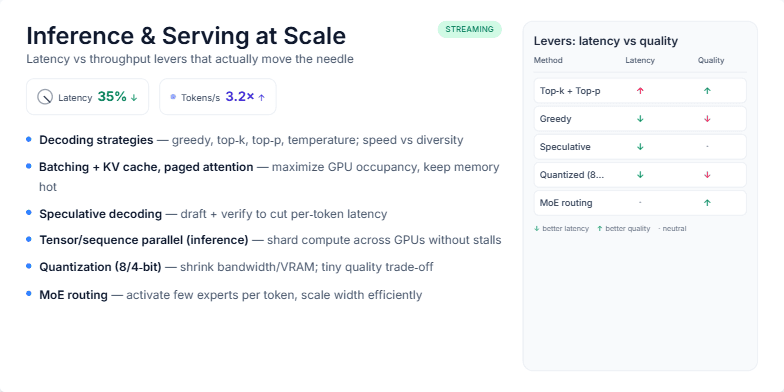
The user requested a technical presentation slide aimed at engineers and data scientists. The slide needs to cover the most effective techniques for optimizing Large Language Model (LLM) inference and serving at scale. It should explain key methods like decoding strategies, KV caching, speculative decoding, and quantization. A key requirement is to visually represent the trade-offs, specifically how each technique impacts latency versus model output quality. The slide should also include key performance indicators, like percentage reduction in latency and increase in tokens per second, to quantify the benefits of these optimizations.
A user requested a presentation slide that visually compares three fundamental patterns for building advanced Large Language Model (LLM) applications: Retrieval-Augmented Generation (RAG), Function Calling, and Agentic Loops. The goal is to explain how these techniques contribute to creating AI systems that are both 'grounded' in facts and 'capable' of performing actions. The user asked for a clean, three-column layout, with each pattern having its own distinct color scheme, a simple diagram, and a list of practical development tips for implementation.
The user requested a presentation slide that explains and compares three key techniques for aligning large language models with human preferences: Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO). The goal is to visually break down the process of each method, provide a clear side-by-side comparison of their characteristics like data intensity, stability, and compute requirements, and conclude with the overarching importance of safety layers that are applied regardless of the chosen training method.
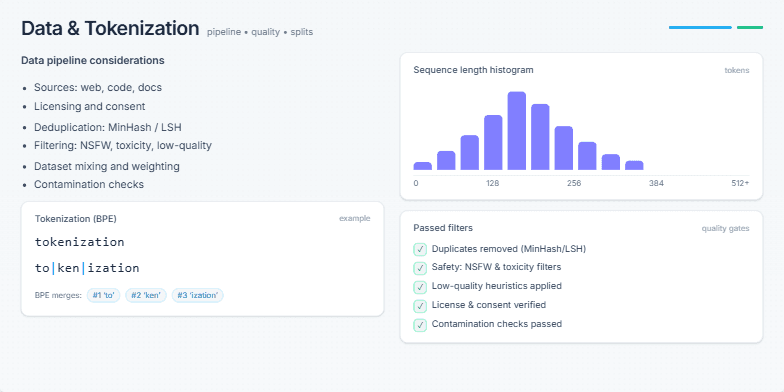
This slide was designed to provide a comprehensive yet digestible overview of the crucial pre-training stage for large language models: data preparation and tokenization. The user needed to explain the multi-step data pipeline, from sourcing and licensing to cleaning and filtering. It also needed to visually demystify the concept of tokenization using an example like Byte-Pair Encoding (BPE). The goal was to combine conceptual points with concrete visuals like a data distribution histogram and a quality assurance checklist to illustrate the entire process effectively.
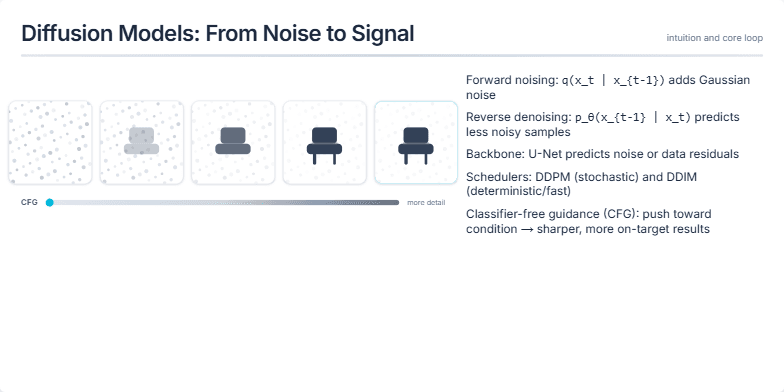
Create a presentation slide that visually explains the core intuition behind diffusion models. The slide should be titled 'Diffusion Models: From Noise to Signal'. On one side, show a visual progression from pure noise to a clear image (like a chair) in several steps. On the other side, list out the key concepts step-by-step: 1. Forward noising, 2. Reverse denoising, 3. The U-Net architecture, 4. Schedulers (DDPM/DDIM), and 5. Classifier-Free Guidance (CFG). Animate each point to appear with its corresponding visual step. For the final point on CFG, add a visual element like a slider to represent guidance strength.
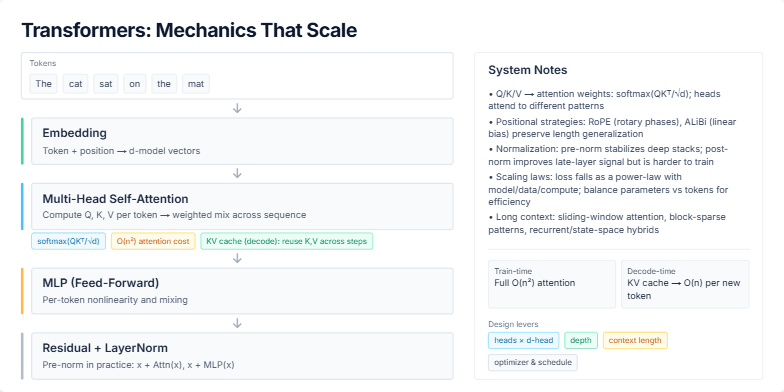
The user requested a slide that explains the forward pass of a Transformer model, titled "Transformers: Mechanics That Scale". The slide needs to visually walk through the main components, starting from input tokens and proceeding through embedding, multi-head self-attention, the MLP, and residual/norm layers. It should connect these mechanics to system-level choices and optimizations, such as the O(n²) cost of attention, the role of the KV cache in decoding, positional strategies like RoPE, and the impact of scaling laws on model training and efficiency.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.