An Intuitive Guide to Diffusion Models: From Noise to Signal and Key Concepts
Description provided by the user:
Create a presentation slide that visually explains the core intuition behind diffusion models. The slide should be titled 'Diffusion Models: From Noise to Signal'. On one side, show a visual progression from pure noise to a clear image (like a chair) in several steps. On the other side, list out the key concepts step-by-step: 1. Forward noising, 2. Reverse denoising, 3. The U-Net architecture, 4. Schedulers (DDPM/DDIM), and 5. Classifier-Free Guidance (CFG). Animate each point to appear with its corresponding visual step. For the final point on CFG, add a visual element like a slider to represent guidance strength.
Title: set the frame. We’ll build an intuition for diffusion: how we go from pure noise to a meaningful image.
Step 1: Point to the first tile. Explain the forward process q(x_t | x_{t-1})—we keep adding Gaussian noise until the signal is unrecognizable.
Step 2: Point to the second tile. Introduce the reverse process p_theta(x_{t-1} | x_t)—a learned denoiser that predicts how to remove a little noise at a time.
Step 3: Point to the third tile. Mention that a U-Net is the workhorse predicting either the noise or residual at each step.
Step 4: Point to the fourth tile. Touch on schedulers: DDPM uses stochastic steps; DDIM provides a deterministic path for fewer, faster steps.
Step 5: Draw attention to the CFG bar and the highlighted last tile. Explain classifier-free guidance: increasing guidance pushes samples closer to the condition for sharper detail, at the cost of some diversity. Summarize: iterate denoise, guided by the model and scheduler, to turn noise into signal.
Behind the Scenes
How AI generated this slide
First, the AI conceptualizes the slide's core metaphor: transforming random noise into a structured image, which perfectly illustrates the diffusion process. A simple, recognizable object like a 'chair' is chosen for the visual.
Next, it designs a two-part layout: a visual demonstration on the left and a textual explanation on the right. This separation helps viewers connect the abstract concepts with a concrete example.
The AI then codes modular React components, `Frame` and `Chair`, to represent the visual steps. The `stage` prop is a clever mechanism to control the animation from noise to signal, progressively revealing the chair while reducing the noise.
To align the visuals with the text, the AI uses a `Fragment` component wrapper. This orchestrates a step-by-step reveal, ensuring that each concept point appears simultaneously with its corresponding visual frame, guiding the audience's attention effectively.
For the final concept, Classifier-Free Guidance (CFG), the AI adds an extra highlighted frame and an animated slider. This translates the abstract idea of 'guidance strength' into an intuitive visual control, making a complex topic more understandable.
Finally, it generates comprehensive speaker notes that sync with the slide's animations, providing a script for the presenter to follow, explaining each part of the diffusion model pipeline as it appears on screen.
Why this slide works
This slide excels at demystifying a complex machine learning topic. Its strength lies in the powerful visual metaphor of a chair emerging from noise, which makes the abstract concept of denoising tangible. The synchronized, step-by-step animation of visual frames and text points creates a guided learning path, preventing information overload. By breaking down the process into key components like U-Net, Schedulers, and CFG, it provides a structured overview for learners. The inclusion of a visual slider for CFG is a brilliant touch, effectively communicating how this parameter influences the final output. The clean, modern design and smooth animations using Framer Motion enhance the educational experience, making it both informative and engaging.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is a diffusion model in simple terms?
A diffusion model is a type of generative AI that creates images by reversing a process of adding noise. It starts with a real image, gradually adds random noise until it's unrecognizable (the forward process), and then trains a neural network to reverse this, step-by-step, starting from pure noise to generate a new, clean image (the reverse process). It's like a sculptor starting with a block of marble (noise) and carefully chipping away to reveal a statue (the image).
What is the role of the U-Net in a diffusion model?
The U-Net is the core neural network architecture used in most diffusion models. Its job during the reverse process is to look at a noisy image at a specific step and predict the noise that was added to it. By subtracting this predicted noise, the model can produce a slightly less noisy image. The U-Net's unique 'U' shape with skip connections is particularly effective at processing image data at multiple scales, allowing it to preserve high-level features while refining fine details, which is crucial for high-quality image generation.
How does Classifier-Free Guidance (CFG) improve image generation?
Classifier-Free Guidance (CFG) is a technique used to improve how closely a generated image adheres to its text prompt. The model generates two predictions: one guided by the prompt and one that's unconditional (ignoring the prompt). The CFG scale determines how much to push the final output away from the unconditional prediction and towards the conditional one. A higher CFG scale typically results in images that are sharper and more faithful to the prompt, but it can sometimes reduce creativity and diversity in the output.
What's the difference between DDPM and DDIM schedulers?
DDPM (Denoising Diffusion Probabilistic Models) and DDIM (Denoising Diffusion Implicit Models) are both 'schedulers' that control the step-by-step denoising process. DDPM is the original, stochastic approach that involves a random element in each step, which often requires many steps (e.g., 1000) for a high-quality result. DDIM is a deterministic variant, meaning for the same starting noise, it will always produce the same image. This allows it to produce high-quality images in far fewer steps (e.g., 20-50), making the generation process much faster, which is why it's widely used in practice.
The user requested a presentation slide that explains and compares three key techniques for aligning large language models with human preferences: Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO). The goal is to visually break down the process of each method, provide a clear side-by-side comparison of their characteristics like data intensity, stability, and compute requirements, and conclude with the overarching importance of safety layers that are applied regardless of the chosen training method.
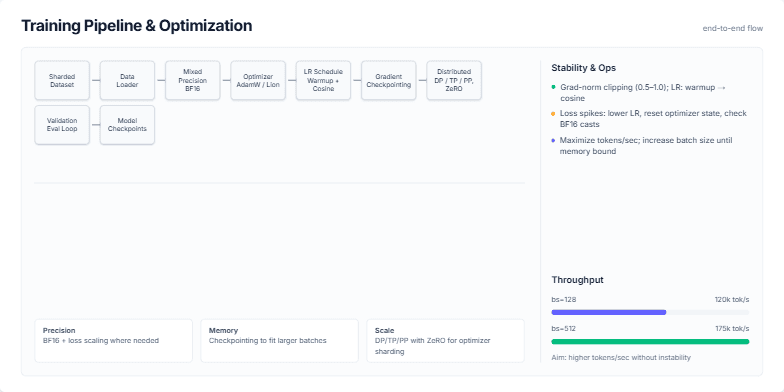
Create a slide that visually breaks down a standard end-to-end training pipeline for a large language model (LLM). It should start from the dataset and go all the way to model checkpoints. For each stage, like data loading, mixed precision, and distributed training, show the key technologies or concepts (e.g., BF16, AdamW, ZeRO). The slide should also include a sidebar with practical tips on ensuring training stability (like handling loss spikes) and a section on optimizing for throughput, showing how batch size affects tokens/second. The overall aesthetic should be clean, technical, and professional.
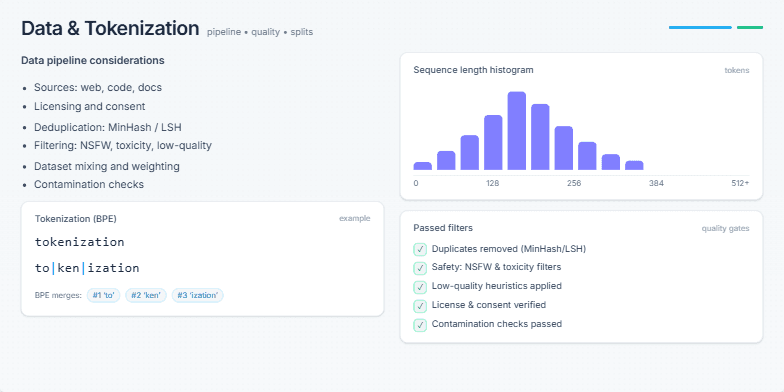
This slide was designed to provide a comprehensive yet digestible overview of the crucial pre-training stage for large language models: data preparation and tokenization. The user needed to explain the multi-step data pipeline, from sourcing and licensing to cleaning and filtering. It also needed to visually demystify the concept of tokenization using an example like Byte-Pair Encoding (BPE). The goal was to combine conceptual points with concrete visuals like a data distribution histogram and a quality assurance checklist to illustrate the entire process effectively.
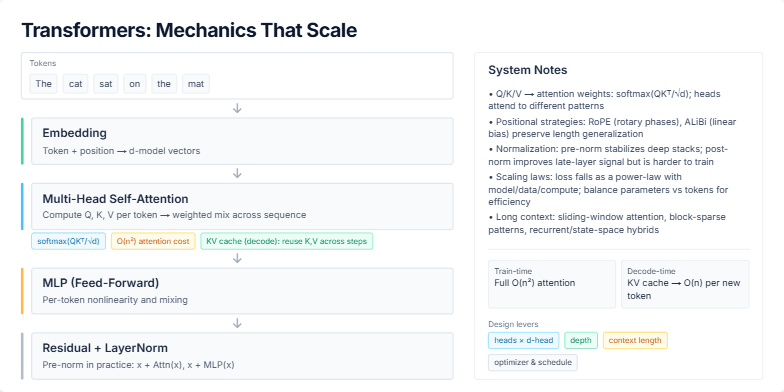
The user requested a slide that explains the forward pass of a Transformer model, titled "Transformers: Mechanics That Scale". The slide needs to visually walk through the main components, starting from input tokens and proceeding through embedding, multi-head self-attention, the MLP, and residual/norm layers. It should connect these mechanics to system-level choices and optimizations, such as the O(n²) cost of attention, the role of the KV cache in decoding, positional strategies like RoPE, and the impact of scaling laws on model training and efficiency.
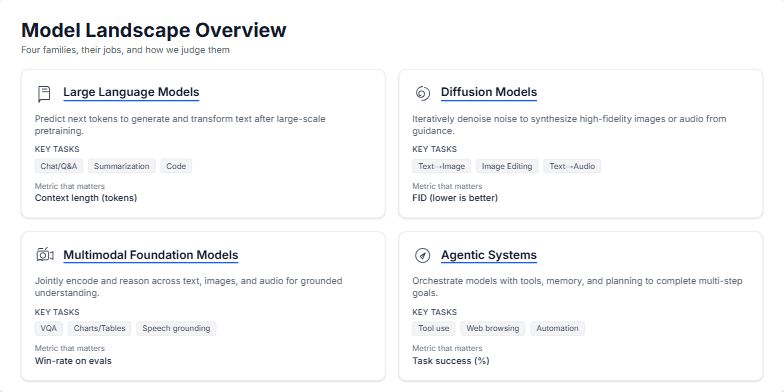
Create a slide that explains the main types of modern AI models. I want to cover four key categories: Large Language Models (LLMs), Diffusion Models for images, Multimodal Models that handle text and images, and Agentic Systems that can take actions. For each one, briefly define it, list a few example tasks, and mention the most important performance metric. The design should be clean, professional, and use a card-based layout to compare them side-by-side. Use simple icons to represent each category. The overall goal is to give a clear, high-level overview for someone new to the field.
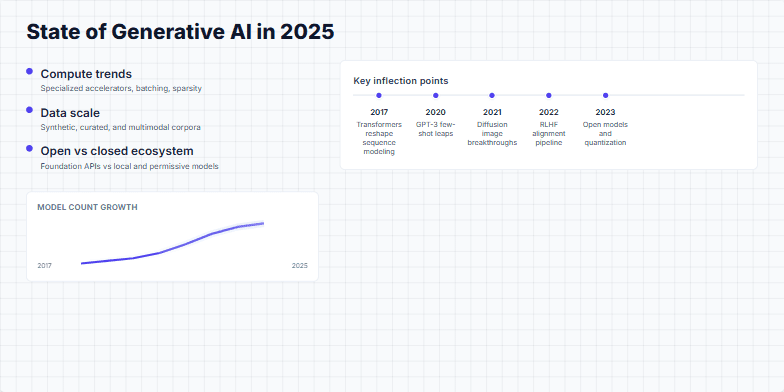
Create a presentation slide that provides a comprehensive overview of the state of Generative AI in 2025. The slide should be structured to first introduce key driving trends like compute, data scale, and the open vs. closed ecosystem. It should then present a historical timeline of major AI milestones from 2017 to 2025, highlighting key inflection points such as Transformers, GPT-3, and RLHF. Conclude with a summary of recent shifts and future-looking priorities like agentic AI and on-device efficiency. The design should be modern, clean, and use data visualization elements like a sparkline chart to illustrate growth.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.