A Comparative Analysis of AI Alignment Techniques: SFT, RLHF, and DPO for Preference Learning
Description provided by the user:
The user requested a presentation slide that explains and compares three key techniques for aligning large language models with human preferences: Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO). The goal is to visually break down the process of each method, provide a clear side-by-side comparison of their characteristics like data intensity, stability, and compute requirements, and conclude with the overarching importance of safety layers that are applied regardless of the chosen training method.
Start by framing the slide: we’re comparing three approaches to alignment through preferences—SFT, RLHF, and DPO.
First, SFT: explain it as learning directly from curated demonstrations via standard supervised learning. It’s stable and straightforward but limited to what’s shown in the demos.
Advance to RLHF: describe the pipeline—start from an SFT model, train a reward model from human preference data, then optimize with PPO. Emphasize improved alignment with human judgments, but note training instability and higher data/compute costs.
Advance to DPO: highlight that it skips the explicit reward model and optimizes a direct objective from pairwise preferences. It’s simpler and typically more stable than PPO-based RL, with lower compute.
Show the comparison table: quickly summarize the trade-offs—data intensity and compute are highest for RLHF; SFT is medium across the board; DPO aims for lower compute with medium data needs and moderate stability.
Finally, bring in the safety overlay: stress that regardless of the method, we layer system prompts, safety classifiers, and refusal policies to guard against unsafe outputs. These are orthogonal controls that wrap around the training approach.
Close by suggesting selection guidance: start with SFT for baseline capability, consider DPO for preference alignment efficiently, and use RLHF when you need the highest fidelity to nuanced human judgments and have the budget to support it.
Behind the Scenes
How AI generated this slide
First, establish a clear title and subtitle to frame the topic of AI alignment and introduce the three core methods: SFT, RLHF, and DPO.
Design a modular React component called `MethodPanel` to represent each technique. This component is designed to be reusable and visually distinct, using props for title, description, process boxes, and color-coding to ensure consistency.
Instantiate three `MethodPanel` components, one for each alignment method. Each panel is populated with specific data for SFT, RLHF, and DPO, highlighting their unique process flows, and is color-coded for easy differentiation (blue for SFT, orange for RLHF, green for DPO).
Incorporate `Fragment` and `framer-motion` animations for a phased reveal. Each panel and the subsequent table appear sequentially, guiding the audience's attention and preventing information overload.
Create a comparative table as the next fragment to summarize the trade-offs between the methods across key metrics: data intensity, stability, and compute. This provides a quick, data-driven overview.
Add a final animated element—a banner discussing safety layers—to emphasize that these controls are a separate, crucial layer applied on top of any core training methodology.
Finally, write detailed speaker notes that correspond to the animated fragments, providing a clear narrative for the presenter to follow, explaining each concept as it appears on the slide.
Why this slide works
This slide is effective because it breaks down a complex topic in AI/ML alignment into digestible, visually organized sections. The use of a reusable `MethodPanel` component creates a consistent and professional look, while color-coding aids in distinguishing between the three methods (SFT, RLHF, DPO). The step-by-step reveal, powered by Framer Motion animations, guides the viewer's focus and builds the narrative logically, preventing cognitive overload. The inclusion of a summary table provides a concise, at-a-glance comparison of key trade-offs, which is excellent for retention. The final point on safety layers adds a crucial layer of practical context, making the information more complete and relevant for real-world applications of large language models. The structure is clear, the design is clean, and the animated delivery enhances understanding.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the main difference between RLHF and DPO?
The core difference lies in their approach to learning from human preferences. RLHF (Reinforcement Learning from Human Feedback) is a two-stage process: it first trains a separate reward model to understand human preferences and then uses that model as a reward function to fine-tune the language model with reinforcement learning (like PPO). DPO (Direct Preference Optimization), on the other hand, skips the explicit reward model step. It directly optimizes the language model on preference data using a specific loss function, which makes it a simpler, single-stage process that is often more stable and less computationally expensive than RLHF.
When should I choose SFT over more complex methods like RLHF or DPO?
SFT (Supervised Fine-Tuning) is the best choice when you have a high-quality, curated dataset of ideal demonstrations (e.g., perfect question-answer pairs). It is highly stable, computationally less intensive than RLHF, and serves as a strong baseline. You should start with SFT to teach the model a core capability. If the model's behavior needs to be further refined based on nuanced human judgments of what is 'better' rather than just 'correct', you would then move on to preference-based methods like DPO or RLHF.
Are the safety layers mentioned on the slide part of the training process for these methods?
Not directly. Safety layers like system prompts, safety classifiers, and refusal policies are typically applied as additional controls on top of the model that has already been trained using SFT, RLHF, or DPO. They are orthogonal mechanisms that act as guardrails during inference time. For example, a system prompt guides the model's behavior for a specific conversation, and a safety classifier might review the model's output before it's shown to the user. These layers are crucial for ensuring safe and responsible AI deployment, regardless of the underlying alignment technique.
What does 'stability' refer to in the comparison table?
In the context of training large language models, 'stability' refers to the consistency and predictability of the training process. A 'High' stability method like SFT has a smooth and reliable training run. A 'Low' stability method like RLHF can be volatile; its performance can fluctuate significantly during training, and it can be difficult to tune hyperparameters to achieve convergence. DPO is often considered to have 'Medium' stability as it is generally more reliable than RLHF but can still present more challenges than the straightforward process of SFT.
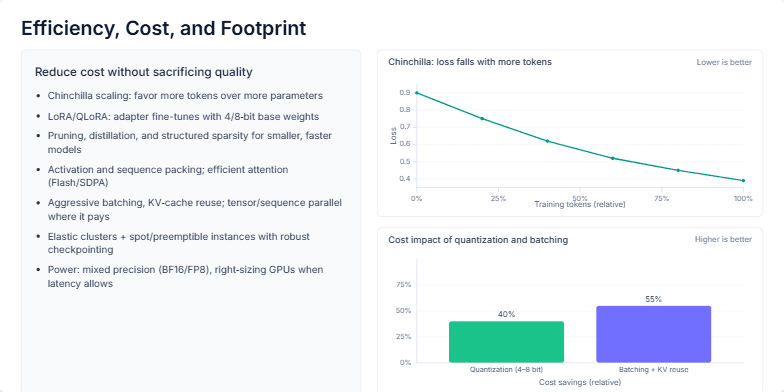
Create a slide for a technical audience about optimizing large AI models. The slide should cover key strategies for reducing cost and computational footprint without sacrificing quality. I want to see a list of techniques, including Chinchilla scaling, LoRA/QLoRA, pruning, and infrastructure tactics like using spot instances. Please include two charts to visualize the impact: a line chart showing how training loss decreases with more tokens (like in the Chinchilla paper) and a bar chart quantifying the cost savings from common inference optimizations like quantization and batching.
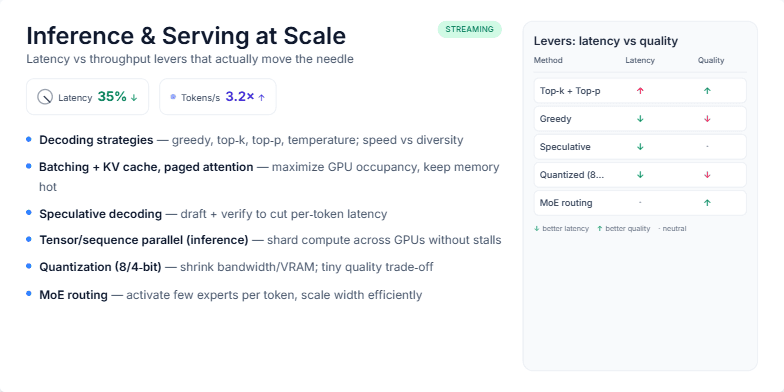
The user requested a technical presentation slide aimed at engineers and data scientists. The slide needs to cover the most effective techniques for optimizing Large Language Model (LLM) inference and serving at scale. It should explain key methods like decoding strategies, KV caching, speculative decoding, and quantization. A key requirement is to visually represent the trade-offs, specifically how each technique impacts latency versus model output quality. The slide should also include key performance indicators, like percentage reduction in latency and increase in tokens per second, to quantify the benefits of these optimizations.
A user requested a presentation slide that visually compares three fundamental patterns for building advanced Large Language Model (LLM) applications: Retrieval-Augmented Generation (RAG), Function Calling, and Agentic Loops. The goal is to explain how these techniques contribute to creating AI systems that are both 'grounded' in facts and 'capable' of performing actions. The user asked for a clean, three-column layout, with each pattern having its own distinct color scheme, a simple diagram, and a list of practical development tips for implementation.
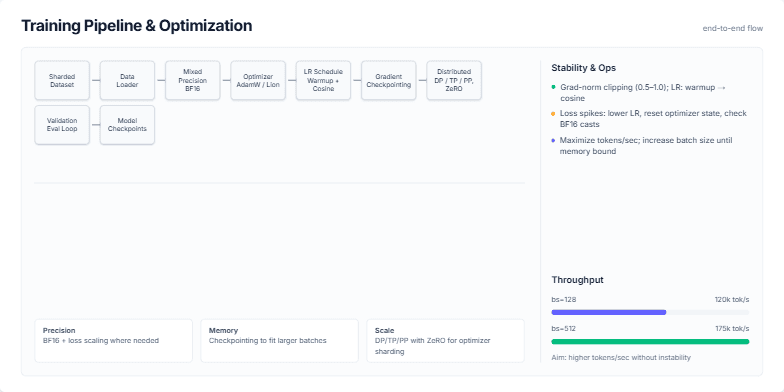
Create a slide that visually breaks down a standard end-to-end training pipeline for a large language model (LLM). It should start from the dataset and go all the way to model checkpoints. For each stage, like data loading, mixed precision, and distributed training, show the key technologies or concepts (e.g., BF16, AdamW, ZeRO). The slide should also include a sidebar with practical tips on ensuring training stability (like handling loss spikes) and a section on optimizing for throughput, showing how batch size affects tokens/second. The overall aesthetic should be clean, technical, and professional.
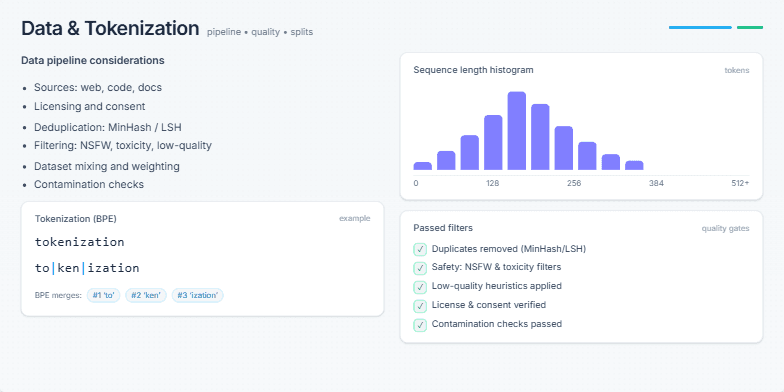
This slide was designed to provide a comprehensive yet digestible overview of the crucial pre-training stage for large language models: data preparation and tokenization. The user needed to explain the multi-step data pipeline, from sourcing and licensing to cleaning and filtering. It also needed to visually demystify the concept of tokenization using an example like Byte-Pair Encoding (BPE). The goal was to combine conceptual points with concrete visuals like a data distribution histogram and a quality assurance checklist to illustrate the entire process effectively.
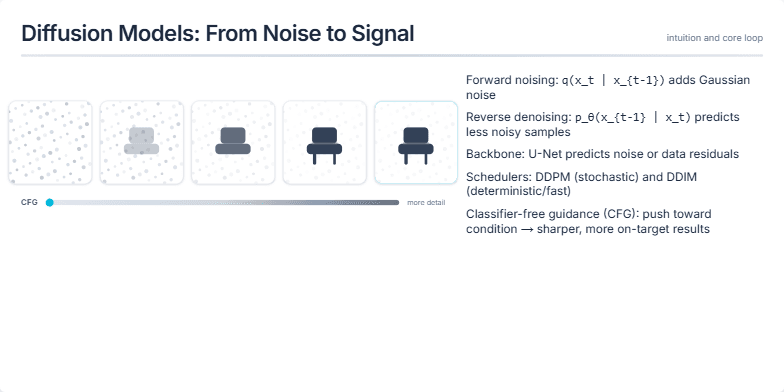
Create a presentation slide that visually explains the core intuition behind diffusion models. The slide should be titled 'Diffusion Models: From Noise to Signal'. On one side, show a visual progression from pure noise to a clear image (like a chair) in several steps. On the other side, list out the key concepts step-by-step: 1. Forward noising, 2. Reverse denoising, 3. The U-Net architecture, 4. Schedulers (DDPM/DDIM), and 5. Classifier-Free Guidance (CFG). Animate each point to appear with its corresponding visual step. For the final point on CFG, add a visual element like a slider to represent guidance strength.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.