Building Grounded and Capable AI Systems with RAG, Function Calling, and Agentic Loops
Description provided by the user:
A user requested a presentation slide that visually compares three fundamental patterns for building advanced Large Language Model (LLM) applications: Retrieval-Augmented Generation (RAG), Function Calling, and Agentic Loops. The goal is to explain how these techniques contribute to creating AI systems that are both 'grounded' in facts and 'capable' of performing actions. The user asked for a clean, three-column layout, with each pattern having its own distinct color scheme, a simple diagram, and a list of practical development tips for implementation.
First, set the frame: we want models that are both grounded and capable. We will walk through three patterns that layer up to that goal.
Start with RAG. Explain the simple flow: embed content, store in a vector database, retrieve relevant chunks, and fuse them into the prompt. Emphasize three practical tips: chunk by structure and semantics with minimal overlap, re-rank retrieved passages before fusion, and always attach citations so outputs are traceable.
Move to function calling. Show how we constrain the model with a JSON Schema. The model fills arguments via a tool call, and constrained decoding keeps outputs well-formed. Encourage versioning and logging of schemas for reliability and observability.
Finish with the agentic loop. Describe the cycle: plan, act via tools or APIs, observe results, and reflect into memory. Keep the loop lightweight: bounded depth, retries and guards on tools, and persistent summaries to improve over time without drifting.
Close by connecting the three: RAG grounds answers, function calling lets the model take precise actions, and the agentic loop stitches those actions into iterative capability.
Behind the Scenes
How AI generated this slide
The AI first deconstructed the request into three core concepts: RAG, Function Calling, and Agentic Loops, under the unifying theme of 'Grounded and capable systems'.
A three-column layout was chosen for direct comparison, with a distinct color variant (sky, emerald, amber) assigned to each concept for clear visual distinction and thematic consistency.
The slide was built using a modular, component-based architecture in React, creating reusable elements like 'ColumnCard', 'NodePill', and 'Arrow' for clean and maintainable code.
For each column, the AI designed a custom diagram component to visually represent the core process: a linear flow for RAG, a JSON schema for Function Calling, and a cyclical loop for the Agent.
Finally, the components were assembled into the main slide structure, and comprehensive speaker notes were generated to guide the presenter through explaining each concept and its practical implications.
Why this slide works
This slide excels at making complex AI engineering concepts accessible through a clear and structured visual design. The three-column layout allows for easy side-by-side comparison of RAG, Function Calling, and Agents. The distinct color-coding for each pattern creates strong visual recall and helps differentiate the concepts. Each column combines a title, a conceptual badge (Grounding, Control, Autonomy), a simplified diagram, and actionable bullet points, providing a multi-layered explanation that caters to both quick glances and deeper dives. The use of Framer Motion for subtle animations adds a professional polish, making the content more engaging. The code itself is clean and follows modern front-end development practices, making it a great example of high-quality web component design.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the main difference between RAG, Function Calling, and Agents?
RAG (Retrieval-Augmented Generation) is for 'grounding'; it connects the AI model to external knowledge to provide factual, verifiable answers with citations. Function Calling provides 'control'; it allows the model to interact with external APIs by generating structured data, like JSON, to call specific functions. Agents represent 'autonomy'; they create an iterative loop (Plan → Act → Observe → Reflect) where the model can use tools (via function calling) and knowledge (via RAG) to complete complex, multi-step tasks. They build on each other: RAG grounds the model, functions give it tools, and agents orchestrate those tools over time.
Why is 'constrained decoding' important for Function Calling?
Constrained decoding is crucial for reliability in Function Calling. When an AI model needs to call a function, it must generate arguments that match a predefined structure, typically a JSON Schema. Without constraints, the model might generate invalid JSON or arguments with incorrect data types, causing the API call to fail. Constrained decoding forces the model's output to conform to the schema during generation, guaranteeing that the output is always valid. This eliminates brittle parsing and error-handling logic, making the entire system more robust and predictable.
What are the risks of using an Agentic Loop and how can they be mitigated?
Agentic loops, while powerful, risk getting stuck in infinite cycles, taking unintended actions, and incurring high costs from repeated model/tool calls. The slide suggests mitigations for these issues. To prevent infinite loops, you should 'cap depth' to limit the number of cycles. To ensure reliability, use 'small, reliable tools' and implement 'retry with guards' logic for tool call failures. To manage state and avoid drift, it's vital to 'persist summaries' of actions and observations in a short-term memory, as highlighted in the 'Reflect' step of the loop.
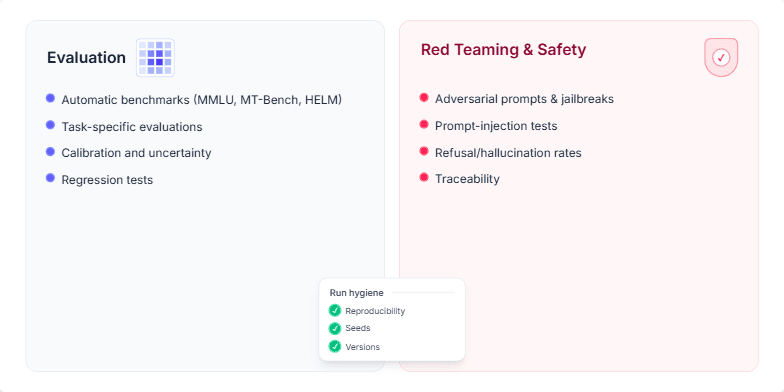
The user requested a slide detailing a company's comprehensive AI model validation process. The slide needed to be split into two main sections: performance evaluation and safety/red teaming. The evaluation part was to include standard benchmarks like MMLU and MT-Bench, task-specific tests, calibration, and regression testing. The safety section required coverage of adversarial prompts, jailbreaks, prompt injection, and metrics like refusal/hallucination rates. A key requirement was to also include a smaller element on 'run hygiene' to emphasize reproducibility, using seeds, and versioning, visually communicating a robust and trustworthy process.
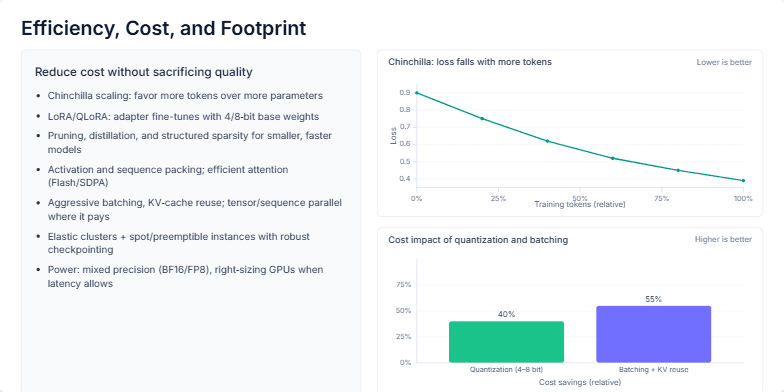
Create a slide for a technical audience about optimizing large AI models. The slide should cover key strategies for reducing cost and computational footprint without sacrificing quality. I want to see a list of techniques, including Chinchilla scaling, LoRA/QLoRA, pruning, and infrastructure tactics like using spot instances. Please include two charts to visualize the impact: a line chart showing how training loss decreases with more tokens (like in the Chinchilla paper) and a bar chart quantifying the cost savings from common inference optimizations like quantization and batching.
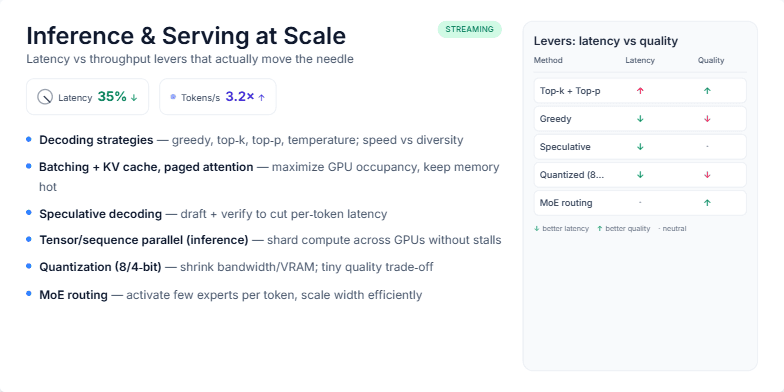
The user requested a technical presentation slide aimed at engineers and data scientists. The slide needs to cover the most effective techniques for optimizing Large Language Model (LLM) inference and serving at scale. It should explain key methods like decoding strategies, KV caching, speculative decoding, and quantization. A key requirement is to visually represent the trade-offs, specifically how each technique impacts latency versus model output quality. The slide should also include key performance indicators, like percentage reduction in latency and increase in tokens per second, to quantify the benefits of these optimizations.
The user requested a presentation slide that explains and compares three key techniques for aligning large language models with human preferences: Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO). The goal is to visually break down the process of each method, provide a clear side-by-side comparison of their characteristics like data intensity, stability, and compute requirements, and conclude with the overarching importance of safety layers that are applied regardless of the chosen training method.
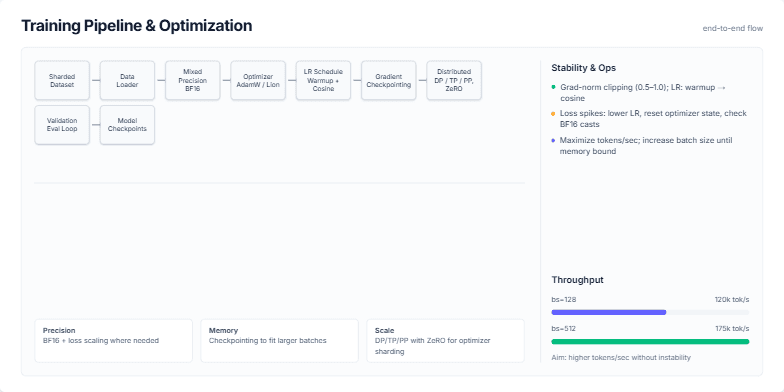
Create a slide that visually breaks down a standard end-to-end training pipeline for a large language model (LLM). It should start from the dataset and go all the way to model checkpoints. For each stage, like data loading, mixed precision, and distributed training, show the key technologies or concepts (e.g., BF16, AdamW, ZeRO). The slide should also include a sidebar with practical tips on ensuring training stability (like handling loss spikes) and a section on optimizing for throughput, showing how batch size affects tokens/second. The overall aesthetic should be clean, technical, and professional.
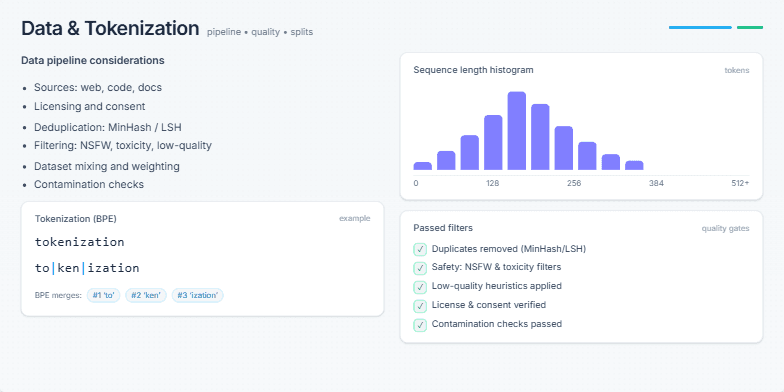
This slide was designed to provide a comprehensive yet digestible overview of the crucial pre-training stage for large language models: data preparation and tokenization. The user needed to explain the multi-step data pipeline, from sourcing and licensing to cleaning and filtering. It also needed to visually demystify the concept of tokenization using an example like Byte-Pair Encoding (BPE). The goal was to combine conceptual points with concrete visuals like a data distribution histogram and a quality assurance checklist to illustrate the entire process effectively.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.