An Overview of the Modern AI Model Landscape: LLMs, Diffusion, Multimodal, and Agents
Description provided by the user:
Create a slide that explains the main types of modern AI models. I want to cover four key categories: Large Language Models (LLMs), Diffusion Models for images, Multimodal Models that handle text and images, and Agentic Systems that can take actions. For each one, briefly define it, list a few example tasks, and mention the most important performance metric. The design should be clean, professional, and use a card-based layout to compare them side-by-side. Use simple icons to represent each category. The overall goal is to give a clear, high-level overview for someone new to the field.
Open by framing the landscape: four families cover most generative use cases. We’ll scan what they do and how we measure them.
First, Large Language Models: they predict tokens to generate and transform text. Typical jobs are chat and Q&A, summarization, and code generation. The key constraint is context length in tokens, which gates how much they can consider at once.
Second, Diffusion Models: they denoise noise to create media. Think text-to-image, image editing, and text-to-audio. We care about FID as a quality proxy, where lower is better.
Third, Multimodal Foundation Models: they reason across text, images, and audio. Use-cases include visual question answering, chart and table understanding, and grounding speech to text. We often compare models by win-rate on standard evaluations.
Fourth, Agentic Systems: they orchestrate models with tools, memory, and planning. Common tasks are tool use, web browsing, and workflow automation. What matters most is task success rate on realistic benchmarks.
Close by linking choices to needs: pick the family that matches your input/output modality; then optimize for the metric that aligns with your product goal.
Behind the Scenes
How AI generated this slide
Deconstruct the request into four distinct AI model categories: Large Language Models, Diffusion Models, Multimodal Foundation Models, and Agentic Systems.
For each category, define the core data points needed for the card: a title, a concise definition, a list of key tasks, and a primary evaluation metric.
Design a reusable `Card` component in React to ensure a consistent look and feel across all four items, using Tailwind CSS for styling the layout, typography, and colors.
Create four custom SVG icon components (`BookIcon`, `SwirlIcon`, `CameraWaveIcon`, `CompassIcon`) to provide a unique visual identifier for each AI model family.
Implement staggered animations using the Framer Motion library. The `Card` component's `animate` prop is triggered with a calculated `delay` based on its order, creating a sequential and visually appealing entrance effect for the grid.
Structure the main slide component with a title section and a 2x2 CSS Grid (`grid grid-cols-2`) to neatly arrange the four cards, ensuring the layout is balanced and easy to compare.
Author detailed speaker notes that expand on each point presented on the slide, providing deeper context and a narrative flow for a presenter to follow.
Why this slide works
This slide is highly effective because it masters information hierarchy and comparative analysis. It takes a complex subject—the AI model landscape—and simplifies it into four digestible categories using a clean, card-based 2x2 grid. This structure allows the audience to easily compare and contrast Large Language Models, Diffusion Models, Multimodal Models, and Agentic Systems. The use of custom SVG icons provides strong visual cues, improving recall. The subtle, staggered entrance animations, powered by Framer Motion, guide the viewer's focus across the slide, making the presentation more engaging and professional. The code is well-organized into reusable React components, demonstrating best practices in front-end development. This clear, structured, and visually appealing design makes it an excellent educational tool for presentations on technology, artificial intelligence, and software innovation.
Slide Code
You need to be logged in to view the slide code.
Frequently Asked Questions
What is the main difference between a Large Language Model and an Agentic System?
A Large Language Model (LLM) is a foundational model focused on processing and generating text by predicting the next token. Its primary capabilities are in tasks like summarization, translation, and question-answering. An Agentic System is a more complex setup that uses an LLM (or another foundation model) as its 'brain' for reasoning and planning. It then orchestrates this model with a set of tools (like web browsers, APIs, or calculators), memory, and a planning module to accomplish multi-step, goal-oriented tasks in an environment. In short, an LLM generates content, while an agent takes actions.
The slide mentions 'FID' for Diffusion Models. What is it and why is it important?
FID stands for Fréchet Inception Distance. It is a popular metric used to assess the quality of images generated by AI models like Diffusion Models. It works by comparing the statistical distribution of features from generated images to that of real images. A lower FID score indicates that the generated images are more realistic and diverse, closely resembling the true data distribution. It's important because it provides a quantitative way to measure progress in image synthesis quality, helping researchers and developers objectively evaluate and improve their models.
Can a single AI application use more than one of these model types?
Absolutely. Advanced AI applications often combine these model types to achieve more sophisticated results. For example, a powerful creative tool might use a Large Language Model to interpret a user's complex text prompt, then feed that refined prompt into a Diffusion Model to generate a high-quality image. An Agentic System could use a Multimodal Foundation Model to understand a user's spoken command and a screenshot they provided, then use tools to browse the web and complete a task based on that combined input. This composition of specialized models is a key trend in building more capable and versatile AI systems.
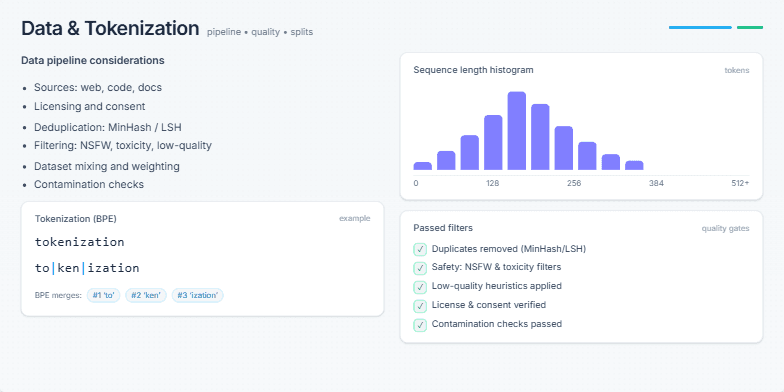
This slide was designed to provide a comprehensive yet digestible overview of the crucial pre-training stage for large language models: data preparation and tokenization. The user needed to explain the multi-step data pipeline, from sourcing and licensing to cleaning and filtering. It also needed to visually demystify the concept of tokenization using an example like Byte-Pair Encoding (BPE). The goal was to combine conceptual points with concrete visuals like a data distribution histogram and a quality assurance checklist to illustrate the entire process effectively.
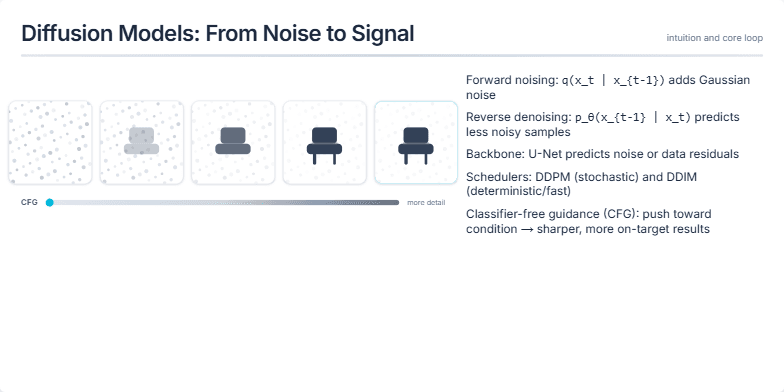
Create a presentation slide that visually explains the core intuition behind diffusion models. The slide should be titled 'Diffusion Models: From Noise to Signal'. On one side, show a visual progression from pure noise to a clear image (like a chair) in several steps. On the other side, list out the key concepts step-by-step: 1. Forward noising, 2. Reverse denoising, 3. The U-Net architecture, 4. Schedulers (DDPM/DDIM), and 5. Classifier-Free Guidance (CFG). Animate each point to appear with its corresponding visual step. For the final point on CFG, add a visual element like a slider to represent guidance strength.
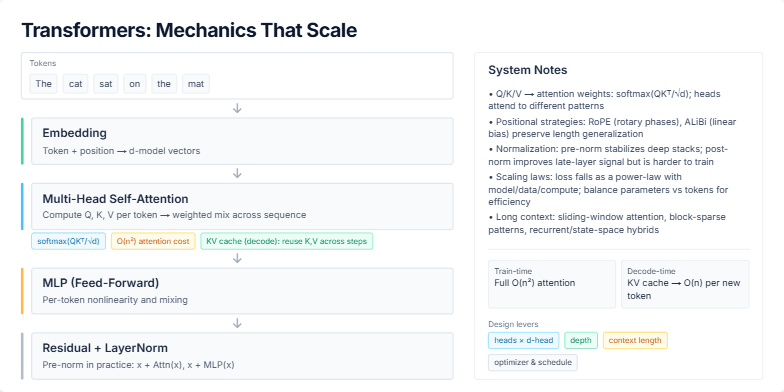
The user requested a slide that explains the forward pass of a Transformer model, titled "Transformers: Mechanics That Scale". The slide needs to visually walk through the main components, starting from input tokens and proceeding through embedding, multi-head self-attention, the MLP, and residual/norm layers. It should connect these mechanics to system-level choices and optimizations, such as the O(n²) cost of attention, the role of the KV cache in decoding, positional strategies like RoPE, and the impact of scaling laws on model training and efficiency.
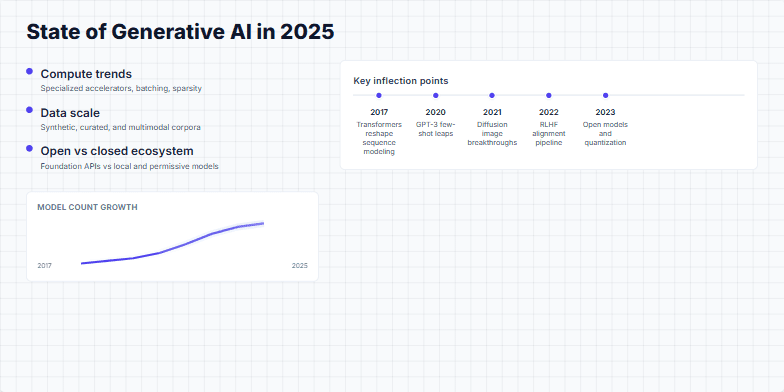
Create a presentation slide that provides a comprehensive overview of the state of Generative AI in 2025. The slide should be structured to first introduce key driving trends like compute, data scale, and the open vs. closed ecosystem. It should then present a historical timeline of major AI milestones from 2017 to 2025, highlighting key inflection points such as Transformers, GPT-3, and RLHF. Conclude with a summary of recent shifts and future-looking priorities like agentic AI and on-device efficiency. The design should be modern, clean, and use data visualization elements like a sparkline chart to illustrate growth.
I need a professional and modern title slide for a tech conference presentation. The topic is 'Generative AI', with the subtitle 'Systems, Scaling, and Safety'. The speaker is Maya Chen, Principal Research Engineer at Vector Labs. The event is the AI Systems Summit 2025 in San Francisco on Oct 8. The design should be dark, sophisticated, and minimalist, using subtle animations to reveal the text elements sequentially. It should have a clean, technical feel. Please also generate detailed speaker notes for a calm, authoritative opening that introduces the topic and sets the agenda for the talk.
Create a slide visualizing a 30/60/90 day roadmap for a project. The roadmap should include key milestones for each phase, such as problem framing and data audit (30 days), MVP model and evaluation harness (60 days), and pilot deployment and monitoring (90 days). The slide should have a clean and modern design, incorporating a progress indicator or timeline element. Include a 'Start' badge to signify the beginning of the roadmap. The slide should also include a subtle visual element to draw attention to the start of the roadmap. A small, unobtrusive QR code linking to relevant documentation or repository should be placed on the slide. The overall tone should be professional and project-oriented, emphasizing clear goals and progress tracking.
Want to generate your own slides with AI?
Start creating high-tech, AI-powered presentations with Slidebook.