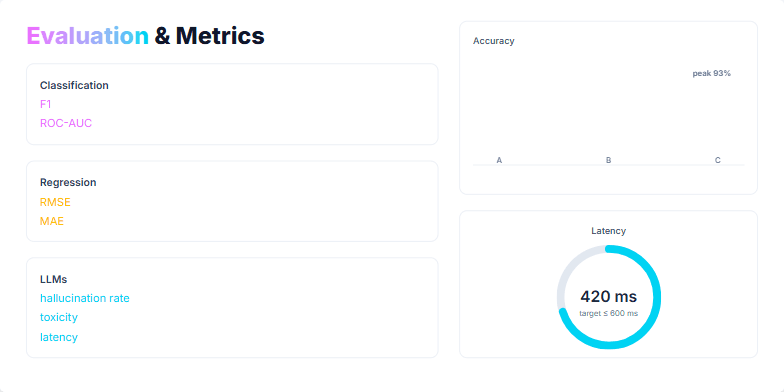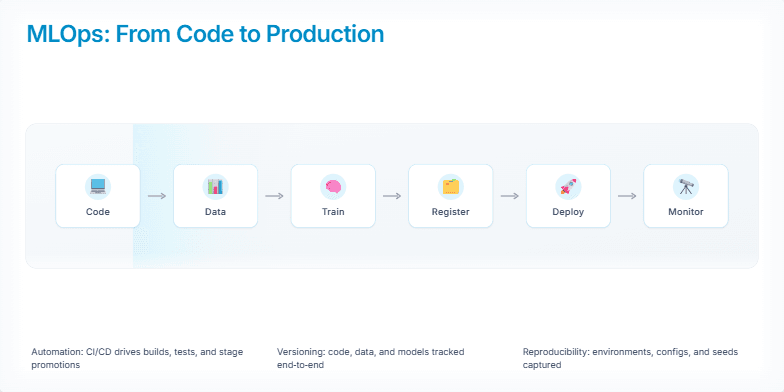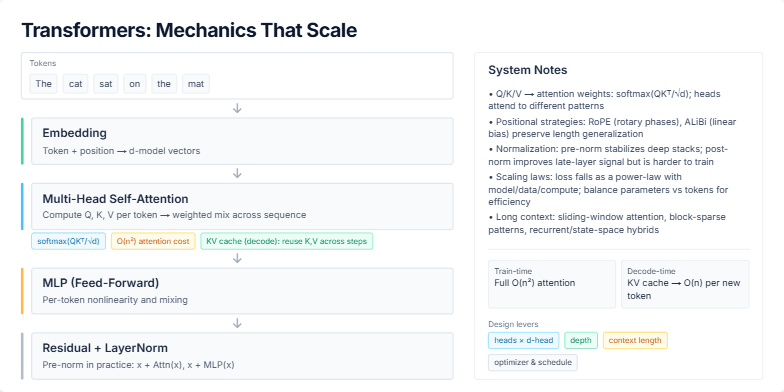
A technical breakdown of the Transformer architecture, focusing on its core mechanics and scaling properties.
The user requested a slide that explains the forward pass of a Transformer model, titled "Transformers: Mechanics That Scale". The slide needs to visually walk through the main components, starting from input tokens and proceeding through embedding, multi-head self-attention, the MLP, and residual/norm layers. It should connect these mechanics to system-level choices and optimizations, such as the O(n²) cost of attention, the role of the KV cache in decoding, positional strategies like RoPE, and the impact of scaling laws on model training and efficiency.